
作者/田然
ChatGPT流行起来之后,快速的出现了一批基于ChatGPT的工具应用,ChatPDF就是其中比较受欢迎的一款。它是一个可以让你与PDF文件进行对话的工具,既可以帮助你快速提取PDF文件中的信息,例如手册、论文、合同、书籍等;也可以根据你的问题,在PDF文件中寻找相关的段落,并用自然语言回答你。
今天,我们就用明道云+ChatGPT+Weaviate实战一下,1个小时内来实现类似的功能。
需求梳理
我们先描述一下最终效果:
| 用户可以上传一个或多个PDF文件,然后向系统用自然语言提问,系统将基于用户上传的PDF文件中的内容给出回复,并给出引用PDF文件的名称和页码;对于PDF文件中没有的内容,系统不能「擅作主张」给出其他超出PDF文件内容范围的答案,而要回复类似于「未找到答案」这样的结果。 |
对这个效果稍加分析,不难看出,需求涉及了两个处理阶段:
- 将用户上传的PDF文件按页码进行拆分,并标注每一页的页码和内容详情;
- 确保ChatGPT可以在用户提问时引用到这些PDF文件的内容,并在文件内容范围内给出回答和引用位置;
其中第1点比较容易,我们可以使用能处理PDF文件的Python库或者JS库在代码块中实现,或者用一些现成的OCR接口来实现。在这个例子里,我们将使用「百度智能云」的办公文档识别API来处理PDF文件内容的分页文字提取 [1]。这个过程可以直接使用明道云「集成中心」中预封装的连接,零代码就能实现,然后用工作表将文字识别的结果存起来。
而对于第2点,对初次接触ChatGPT开发的朋友来说,有点难度。不过我们可以将问题进行如下分解,并逐个解决:
- 怎么让ChatGPT在指定的文本内容范围内回答问题?
- 想要指定范围的文本内容超级大,远远超过了ChatGPT的token数量限制,怎么办?
- 如何在ChatGPT的回答里附加上被引用的PDF文件名称和页码?
- 向ChatGPT提问的内容超出了指定的文本内容范围,如何返回类似「未找到答案」这样固定格式的回复?
解决了这些问题,这个需求自然也就没有任何障碍了。接下来我们来看看从实现原理上,如何让ChatGPT基于我们的PDF个人知识库来回答问题,突破以上限制。
技术原理
怎么让ChatGPT在指定的文本内容范围内回答问题?
要实现这个功能,重点在于编写和改造合适的 prompt 后再向ChatGPT提问。例如大家听说过的「角色扮演法」,让ChatGPT扮演一个角色,基于prompt中给定的上下文背景再作答。其实,更激进一点,让它只能在给定的文本内抽取答案,这个功能就实现了。比如下面的例子:
 |
| chatGPT 在上下文中回复 |
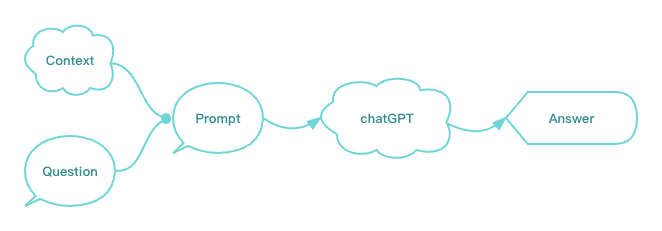
这里使用了一个 prompt 模板,代入上下文(context)和问题(question),ChatGPT将基于上下文来进行回复:
You are a useful assistant for provide professional customer question answering. You can refer to the context to respond to user questions. Must reply using the language used in the user’s question.
Context: {context}
Question: {question}
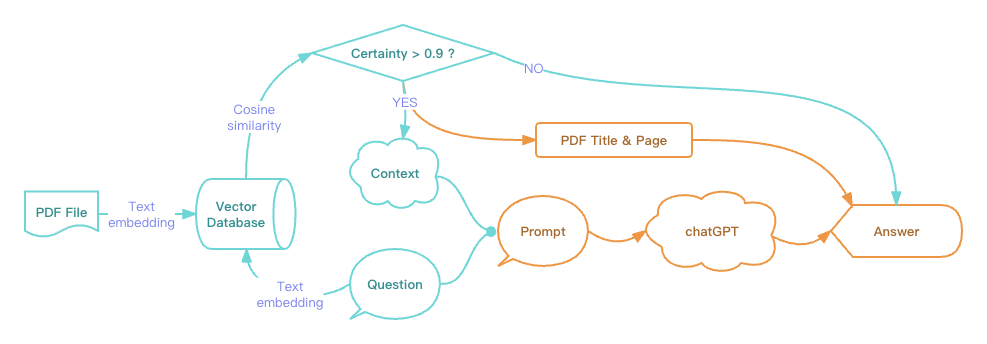
我们可以用一个简单的流程图来表示这种组合方式:
如果问题在上下文里没有找到答案,ChatGPT也会进行简单的「拒绝性」回复:
 |
| chatGPT 上下文中未找到答案时的回复 |
看得出来,ChatGPT即使没有找到答案,也会进行很人性化的回复。如果只是和用户进行聊天式的对话,这样也够用了。但是如果想在上下文中没有找到答案时进行下一步操作,例如调用搜索引擎或者将问题标注为「答案缺失」,这样的回答还无法满足我们的需求。关于这个问题,我们将在后面解决它。
这只是一个简单的prompt模板示例,我们还可以不断地对 prompt 进行修改和调整,并多次测试,直到ChatGPT的回复可以满足我们的需求为止。
想要指定范围的文本内容超级大,远远超过了ChatGPT的token数量限制,怎么办?
解决了上一个问题,我们似乎找到了让ChatGPT在PDF文件内容范围内回答问题的方法。那么,是不是我们将整个PDF文件的内容作为 context 传给ChatGPT,就能让它基于PDF文件来回复我们的问题了?
是的,就像你知道的那样,答案是不太行。原因在于我们使用ChatGPT提供的API接口时,有严格的token数量限制(token数量是ChatGPT按请求内容字数计费的标准,通常来说,一个英文单词计为1个token,而一个中文字符大约计为1个token [2],感觉略坑吧,这也是建议大家尽量使用英文的原因之一):我们常用的 GPT-3.5 接口,请求时最大支持4096个token,这包括了提问和回答的所有字符;就算是价格贵几十倍的GPT-4,最大支持也不过3万2千个token。
因此,我们需要一种既能减少context的文字数量,又让它包含尽量准确的上下文信息的方法。这种方法就是「文本相似性搜索」。
文本相似性搜索基于两个技术:文本嵌入(Text Embedding)和余弦相似度(Cosine Similarity)搜索。
简单来说,就是用文本嵌入技术将自然语言转换成一个高维度空间的数值向量(Vector),这个转换的结果是通过大量的神经网络模型训练来获得的,可以保留文本转成向量后的语义关系 [3] 。也就是说,意思越相近的两个词,它们在向量空间里的位置就越接近,而且它还是兼容多种语言的。比如,世界上所有语言的「你好」,转换成向量后,它们的数值几乎是相等的。
最后,把要搜索的文本转成向量后使用余弦相似度搜索向量数据库(Vector Database),就可以得到按语义相似度排序之后的结果——这个结果通常有两个指标:距离(Distance)和相似确定性(Similar Certainty),它们的值都在0-1之间,越相似的结果,距离值越小、相似确定性值越大。有也一些数据库搜索结果中直接给出了一个相似度评分(Score),意思也都差不多。
我们把PDF文件按页拆分后,就可以用文本相似性搜索先搜索到和提问的语义最接近的那一页,然后只把那一页的文本作为context组合到prompt里传给ChatGPT,这样就能达到我们想要的效果了。
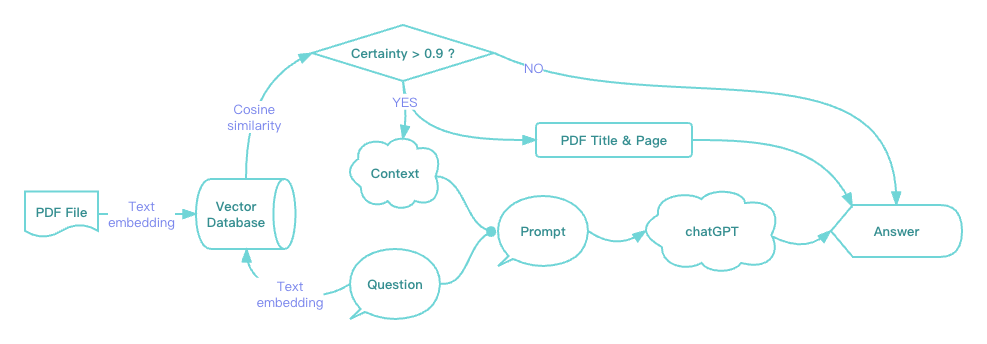
加上这个过程后,把上面的流程图稍加改造表示一下新的流程:
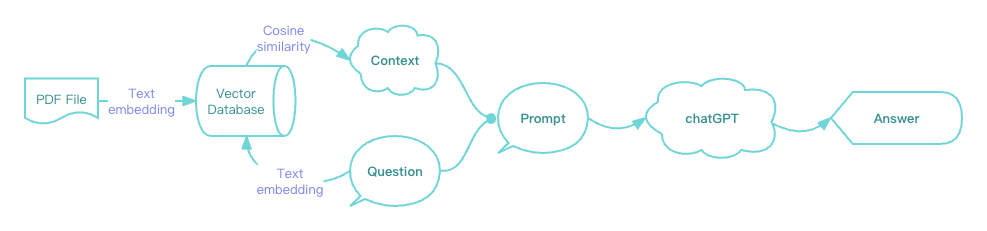
其中的向量数据库有很多种选择,本示例里使用的是 Weaviate(Cloud 版本),因为它不仅内置了OpenAI 的文本嵌入 (Text Embedding) 接口可以在用户无感知的情况下执行文本转向量,还提供了非常完善的REST API。明道云集成中心里也已经预置了Weaviate的API,可以零代码直接使用。
如何在ChatGPT的回答里附加上被引用的PDF文件名称和页码?
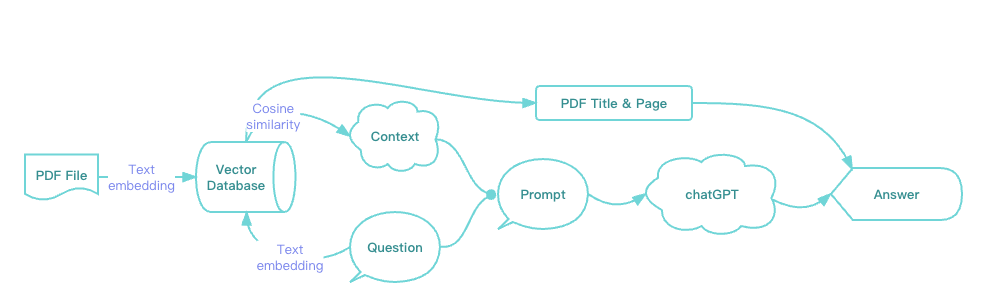
要在答案里附加上PDF的信息,有两种方法:
第一种是把PDF文件名称和页码,都组合到prompt里面,并修改prompt让ChatGPT在回复时给出文件和页码信息;
第二种就是我们在组合prompt前就把向量数据库里返回的排名最高的PDF文件和页码拿到,直接组合到最终输出给用户的答案中。
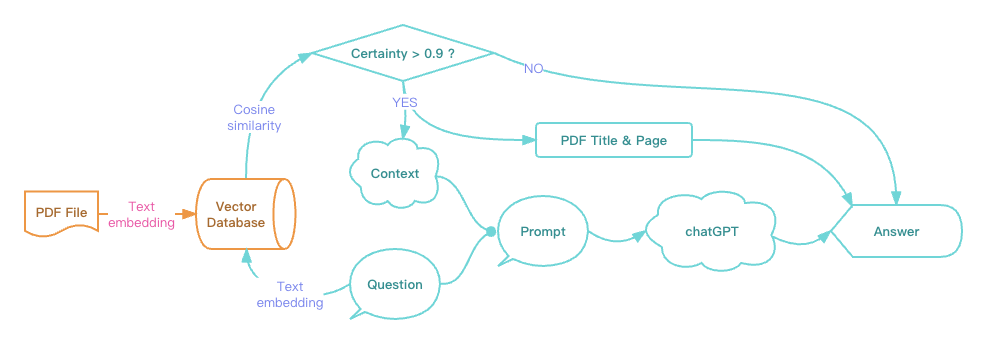
ChatPDF使用的是第一种,在这个例子里,我们采用第二种,流程图修改如下:
向ChatGPT提问的内容超出了指定的文本内容范围,如何返回类似「未找到答案」这样固定格式的回复?
刚才我们说过了,即便不特别处理,在prompt的约束下,ChatGPT也不会胡乱给一个答案凑数,尤其是在请求时 temperature 参数设置为 0 的时候(该参数用于调节ChatGPT输出结果的确定性,值在0-2之间,值越大结果越随机也越有创意) [4]。 但如果要想一个格式化的答案,我们则要另想办法。
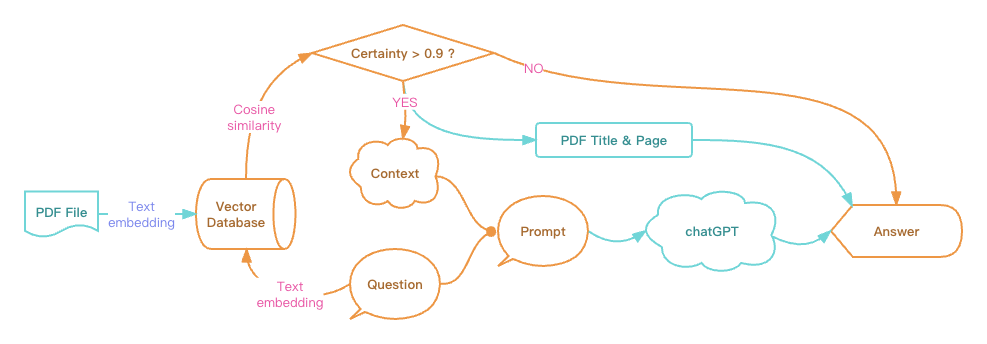
在上面从向量数据库进行相似性搜索的时候,我们已经知道搜索的结果会按照相似度进行排序,并且会给出搜索结果的相似确定性值。那么,我们就可以为相似确定性设置一个阈值,大于这个值的结果,我们认为它符合我们对相似度的定义,其结果可以被用作上下文组合到prompt里;而小于这个值的结果,我们认为它的相似度还不够,即便把它作为上下文组合到prompt里,用户也可能得到风马牛不相及的答案。
按这个规则,如果没有搜索到符合相似度的结果,那我们就不用再向ChatGPT提问了,直接向用户返回「未找到答案」即可。当然,这个阈值要经过多次测试,找到一个平衡点。在这个例子里,我们假设90%相似的结果才有用,所以把这个阈值设为 0.9,所有相似度搜索结果的相似确定性值小于0.9的,我们就认为它的相似度不够,找不到答案。
我们最终的流程图修改如下:
实现过程
一、工具准备
- 明道云专业版账号或私有部署版(https://mingdao.com 免费注册体验14天专业版,私有部署版需要能访问公网及OpenAI接口)
- 百度智能云开发者账号(https://cloud.baidu.com/ 实名认证后可申请文字识别免费次数)
- Weaviate Cloud 账号或安装本地版(https://weaviate.io/ 免费注册体验14天,本地部署需要有公网地址且可以访问OpenAI接口)
- OpenAI API Key(https://platform.openai.com/account/api-keys 需要使用 embedding接口)
二、PDF文档处理
我们先在明道云里实现上传PDF文件后将文档分页识别,把文字识别结果存储到工作表内,并将内容转换成向量存储到向量数据库。这里的实现思路分成以下几个步骤:
- 用户上传PDF文件到明道云工作表;
- 上传完成后自动触发工作流,调用百度文档识别API逐页识别文字;
- 所有页码处理完成后,自动将所有页面的内容批量上传至向量数据库Weaviate(需要先创建集合,上传内容时Weaviate会自动调用OpenAI的Embedding接口执行文本转向量);
- 当工作表里的文字内容有变动时,自动同步到向量数据库;
- 当工作表里的PDF文档被删除或者某一页的内容被删除时,自动删除向量数据库里对应的内容;
2.1 创建向量数据库集合
要完成文本相似性搜索,我们必须要先把文本转成向量存储到向量数据库,然后再用文本的向量进行搜索。注册好 Weaviate Cloud Services 账号,创建一个免费的沙盒环境 [5]。创建完成后,会自动生成 Cluster URL,这个地址我们等一下会用到;如果创建时开启了认证(Authentication),则需要把认证信息中的Admin API Key也复制下来(下图中的钥匙图标处)。
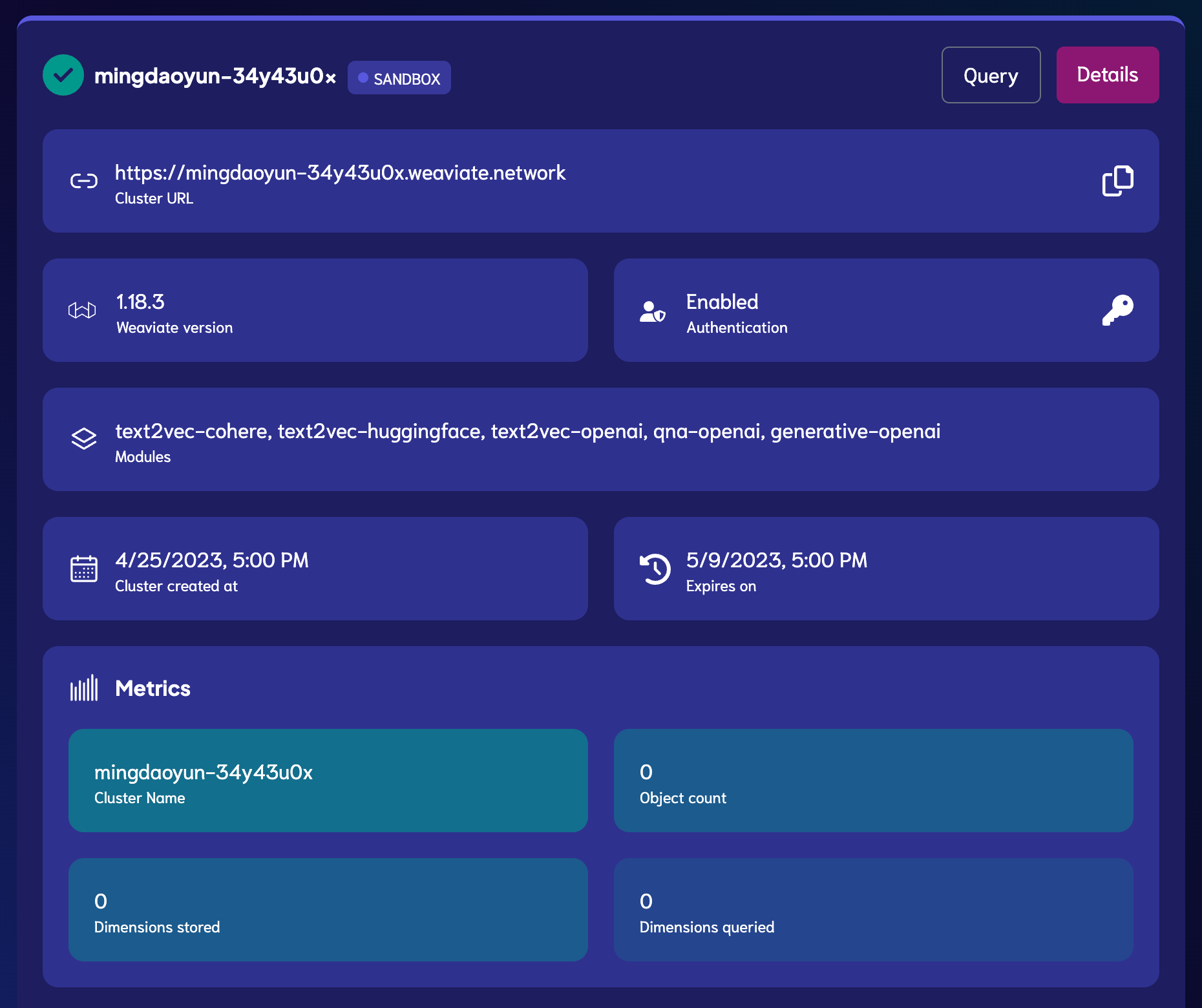 |
| 创建好的 Weaviate Cluster |
接下来在明道云创建一个应用,在集成中心里搜索 Weaviate,安装连接后填写好上一步获得的 API Key 和 Cluster URL,并授权到刚刚创建的应用。还需要在连接参数里配置好 OpenAI 的 API Key,上传数据到向量数据库时会用到。
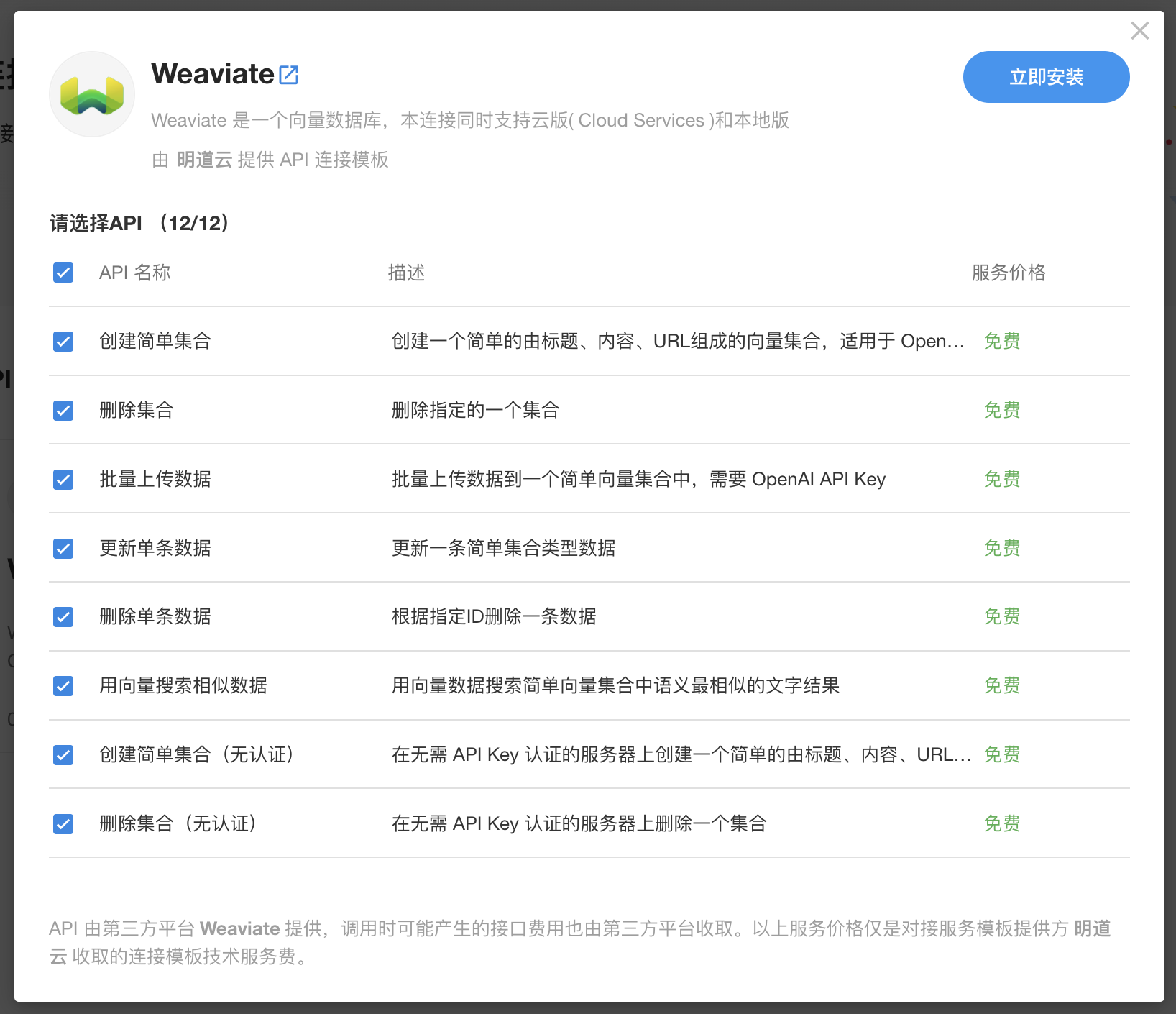 |
| 在明道云集成中心安装 Weaviate |
明道云把Weaviate的API做了比较深度的封装,提供了一个「创建简单集合」的API,只需要传入集合名称和说明,就可以创建一个有「标题」、「内容」、「URL」、「拥有者」四个字段的集合,其中的「标题」和「内容」参与向量搜索,「URL」和「拥有者」仅做为数据存储。在使用「用向量搜索相似数据」API时,将严格按照传入的「拥有者」参数进行筛选,用于用户数据隔离。
我们在明道云里创建一个管理集合的工作表,并建立新增和删除工作表时自动触发工作流,创建和删除Weaviate上的集合。
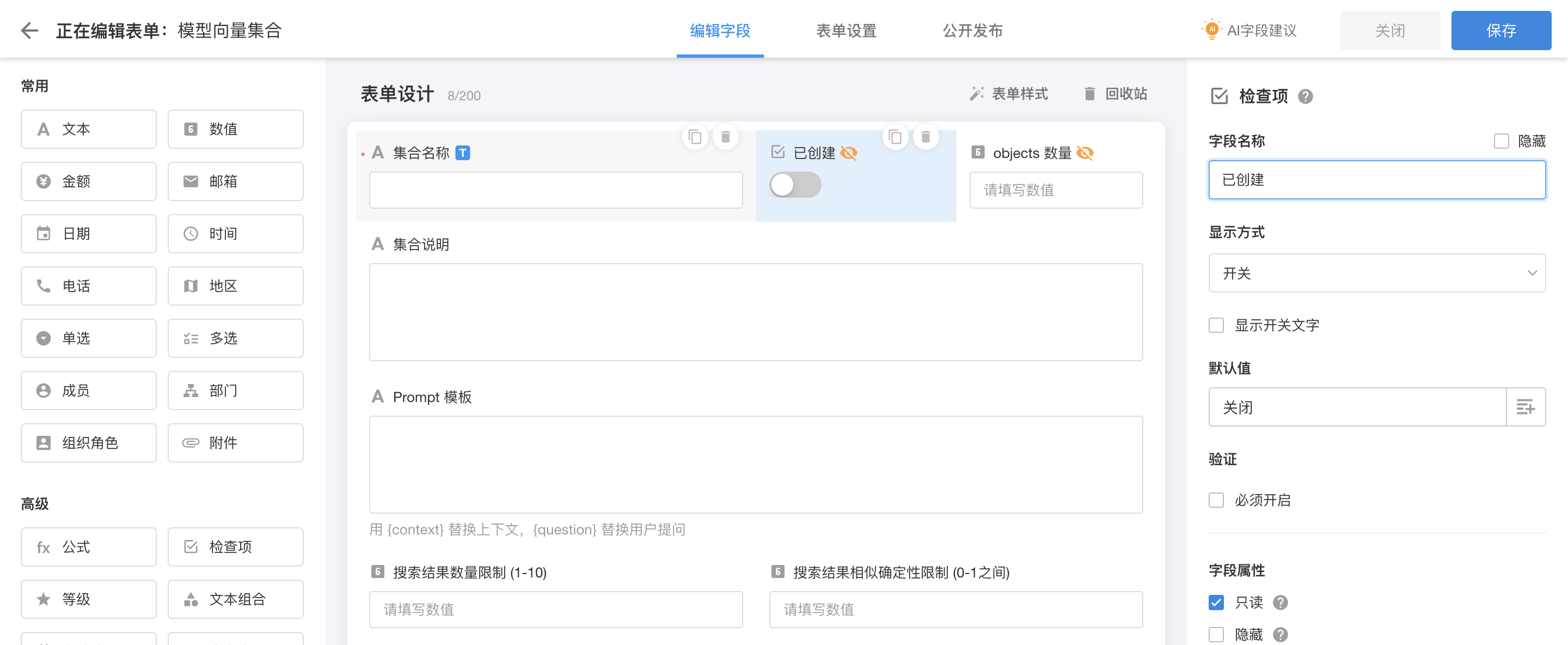 |
| 工作表:模型向量集合 |
为了便于扩展,这里设计的是一个通用的模型集合。ChatPDF只是其中的一个模型,我们把prompt模板、搜索结果数量限制和相似确定性限制都参数化,便于以后我们用于其它业务场景。由于集合创建后不能修改,所以我们需要为工作表设置「业务规则」,限制集合创建后,不能修改名称和说明。
 |
| 业务规则 |
这里的自动化工作流内容比较简单,里面只有「调用已集成API」节点,向Weaviate发起对应的请求。
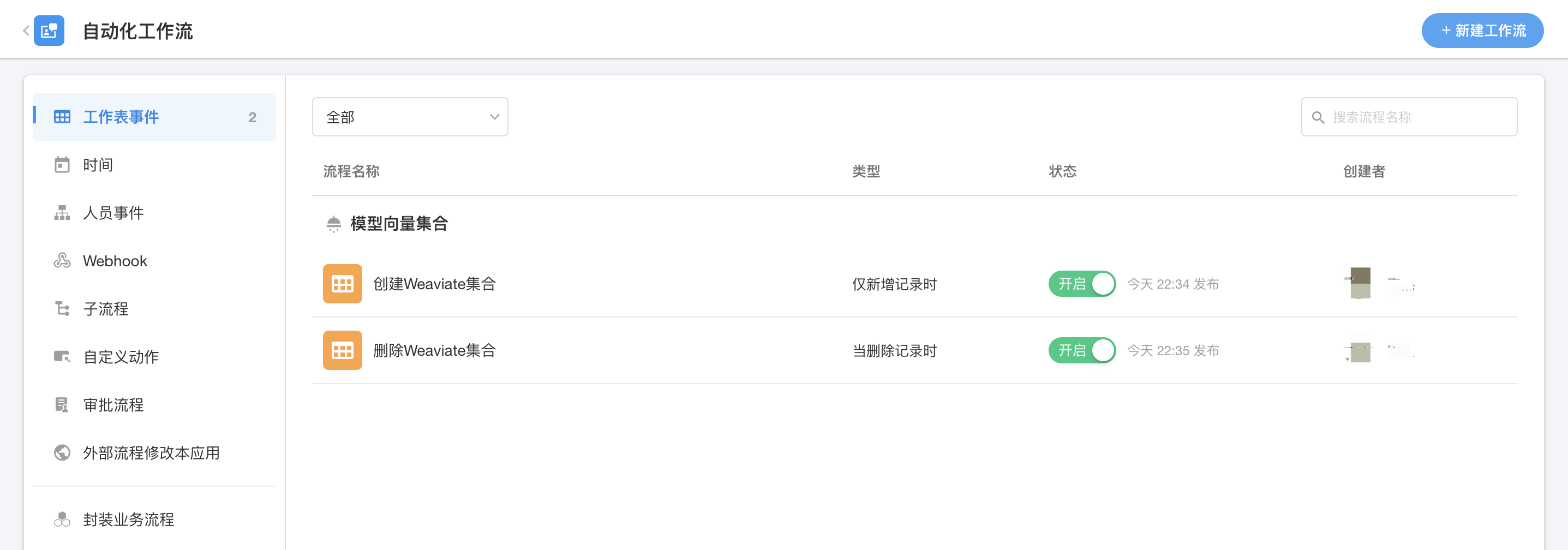 |
| 自动化工作流:自动创建和删除Weaviate集合 |
创建完成后,向工作表添加一条数据,Weaviate上也会新增一个集合。
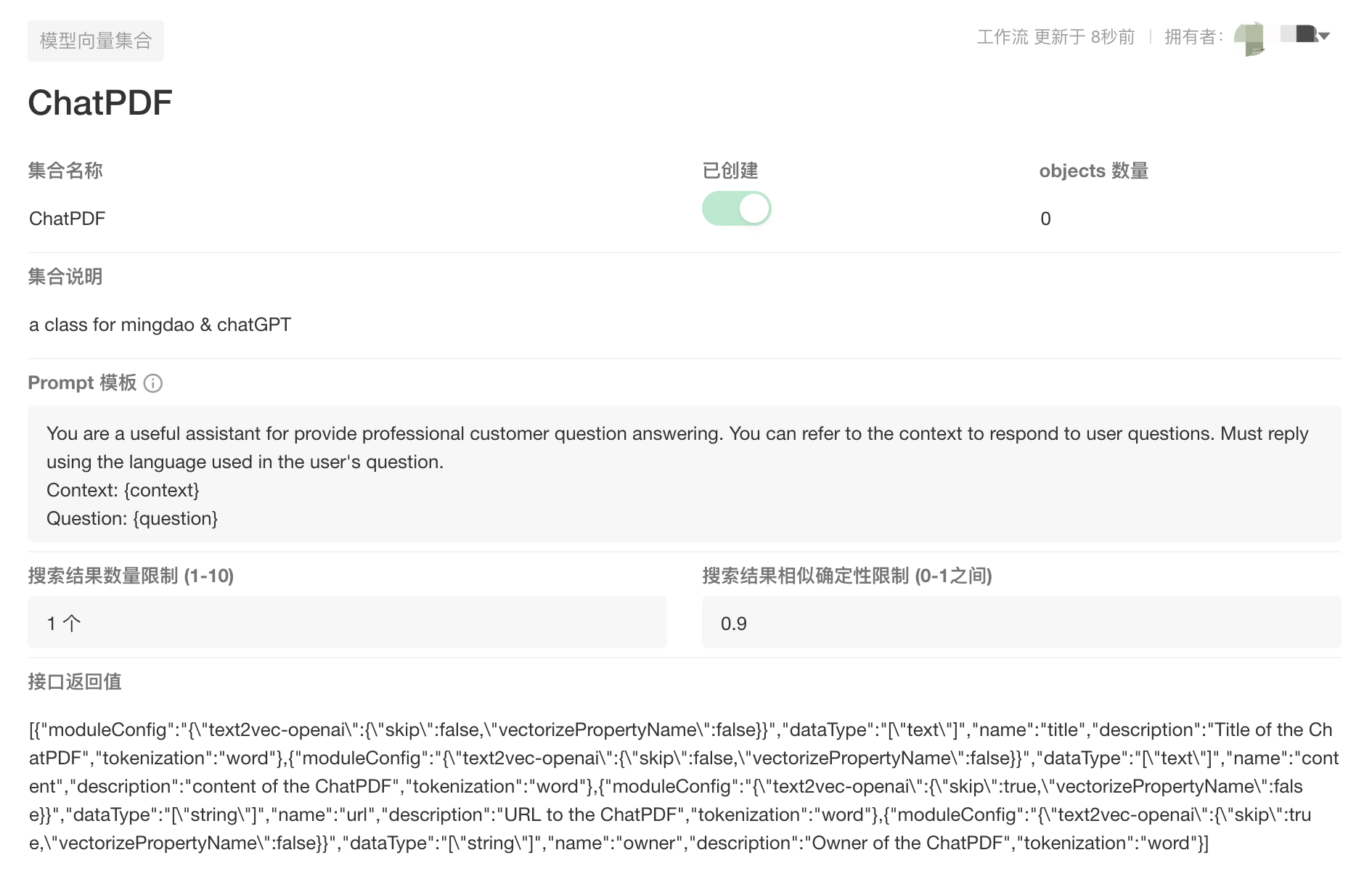 |
| 创建好的集合 |
2.2 识别PDF文档
我们在明道云里创建两张工作表用于存放文档资料:「主文档」、「文档内容明细」。其中,「文档内容明细」是「主文档」的子表,前者存放的内容与向量数据库中存放的内容是一一对应的,所以它的结构也是按照向量数据库的字段结构来设计的;后者主要用于存放用户上传的PDF文档。
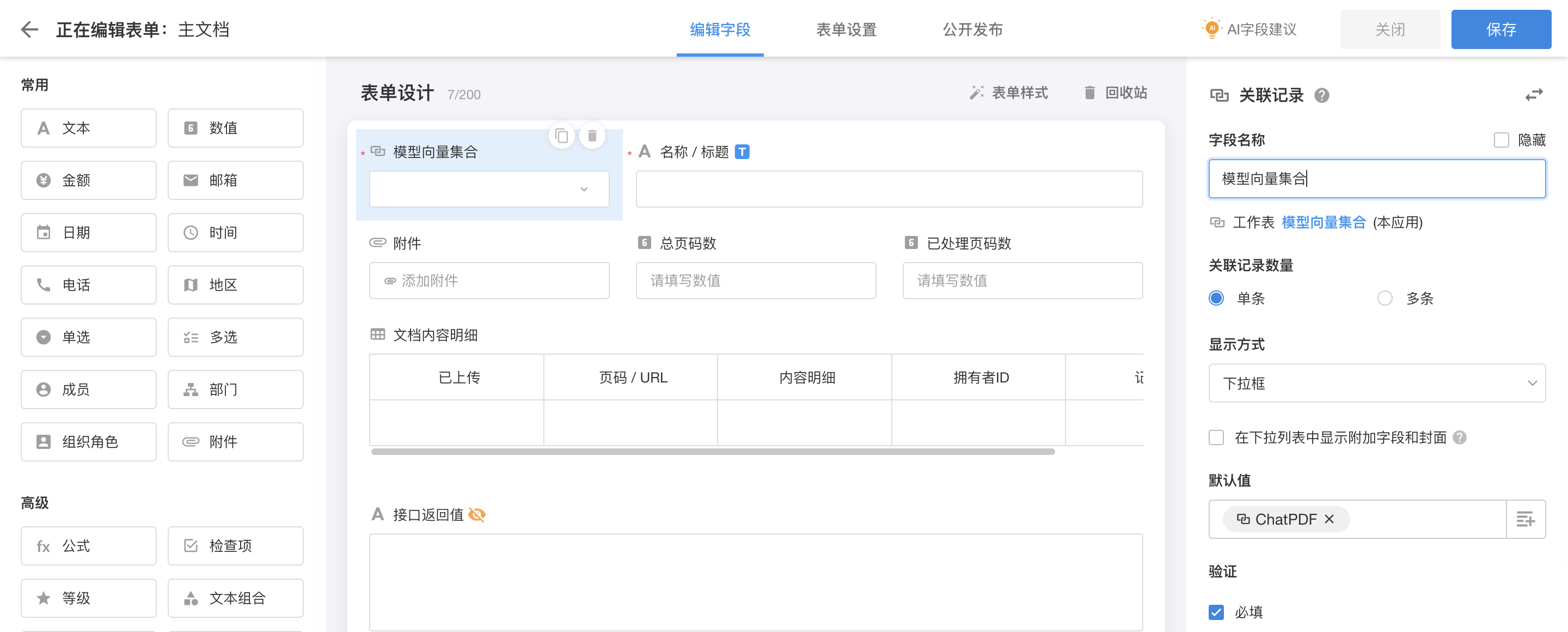 |
| 工作表:主文档(主表) |
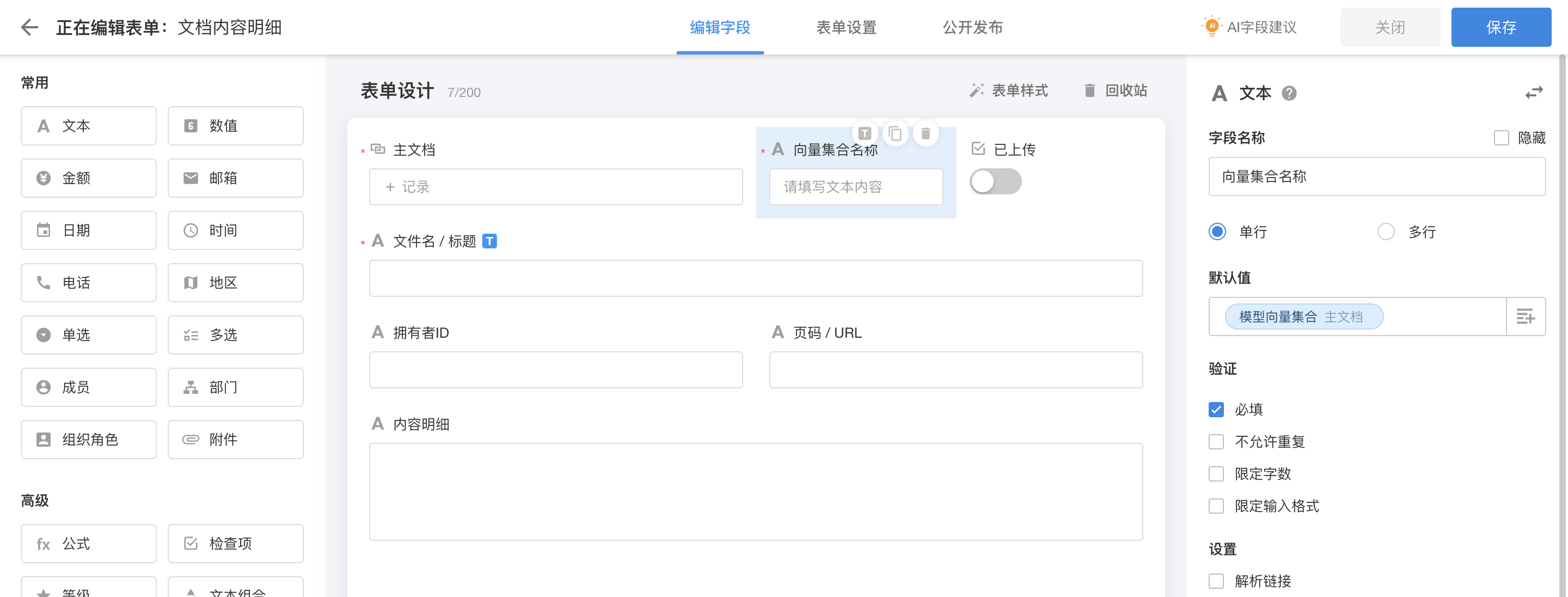 |
| 工作表:文档内容明细(子表) |
主表关联了「模型向量集合」表,子表用文本存储集合名称,它们的默认值都设置为刚刚创建的「ChatPDF」集合。然后我们需要为这两张工作表添加自动化工作流,在用户上传文件后自动完成文字识别和上传到Weaviate的动作。
在开始搭建工作流之前,还需要在「集成中心」里安装「百度云办公文档识别」的API,并在连接里配置好百度云的 API Key 和 Secret Key等信息。
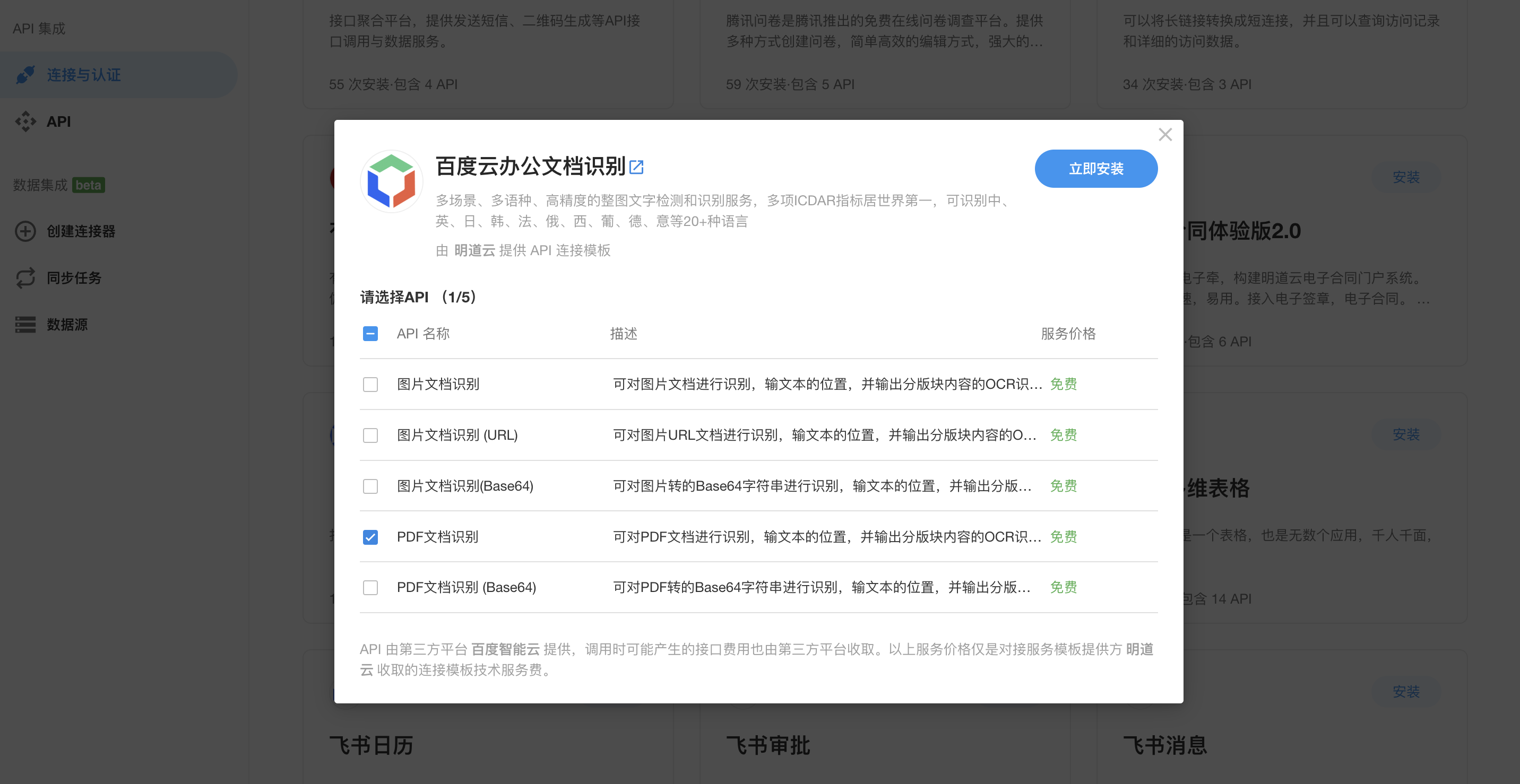 |
| 在集成中心安装PDF识别API |
在处理PDF文字识别的工作流中,有一个循环调用文字识别接口处理PDF文档每个页面识别结果的过程,由于文字识别接口有并发请求量的限制,我们可以在工作流里添加「逐条执行」的「子流程」或者「封装业务流程」来实现,为了复用性,我们这里采用了「封装业务流程」——它就像一个自定义封装的「函数(Function)」,没有固定的触发器,只有输入和输出参数,可以在任意位置被其他工作流调用 [6]。
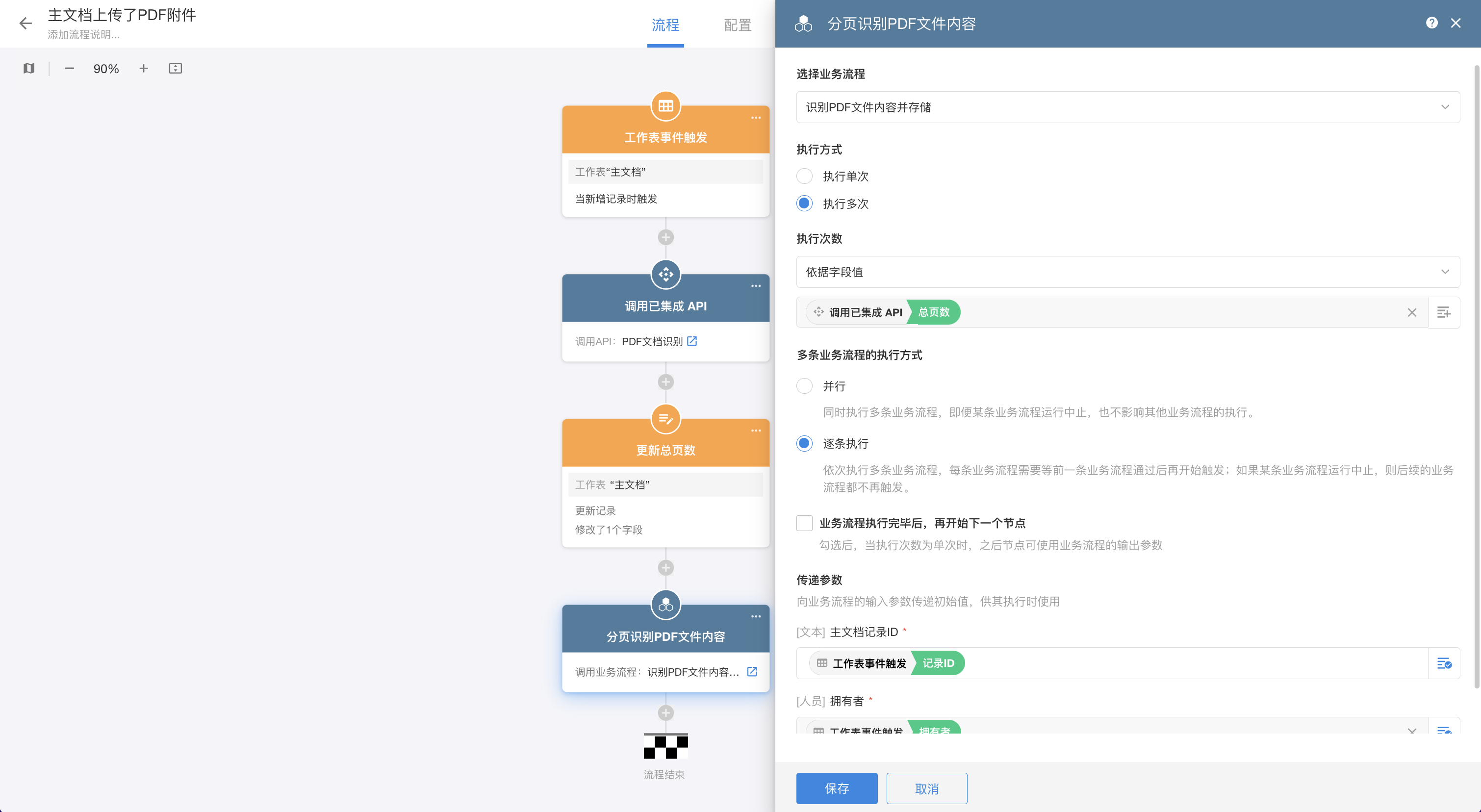 |
| 使用封装业务流程处理分页文字识别 |
在所有页面的文字识别完成后,我们会调用Weaviate的批量上传API一次性把所有结果都上传到向量数据库(必须配置好 OpenAI API Key)。接着还要处理一下更新和删除的逻辑,当手动更新和删除文档内容明细的数据时,要及时的同步到向量数据库中。
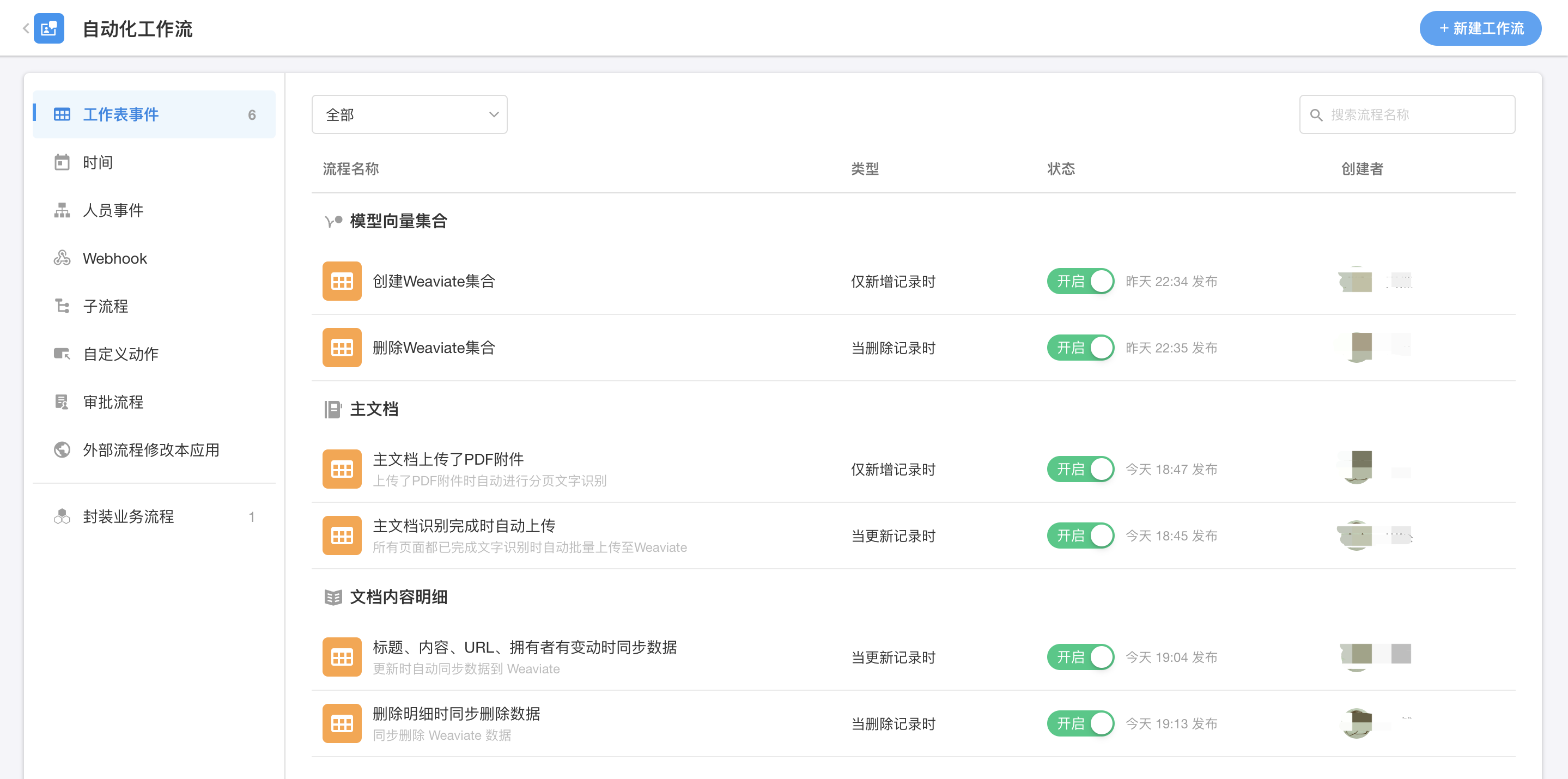 |
| 完成PDF识别步骤后的自动化工作流 |
至此,PDF文档的处理步骤就完成了。用户上传PDF文件后,会自动完成分页、识别和上传动作。
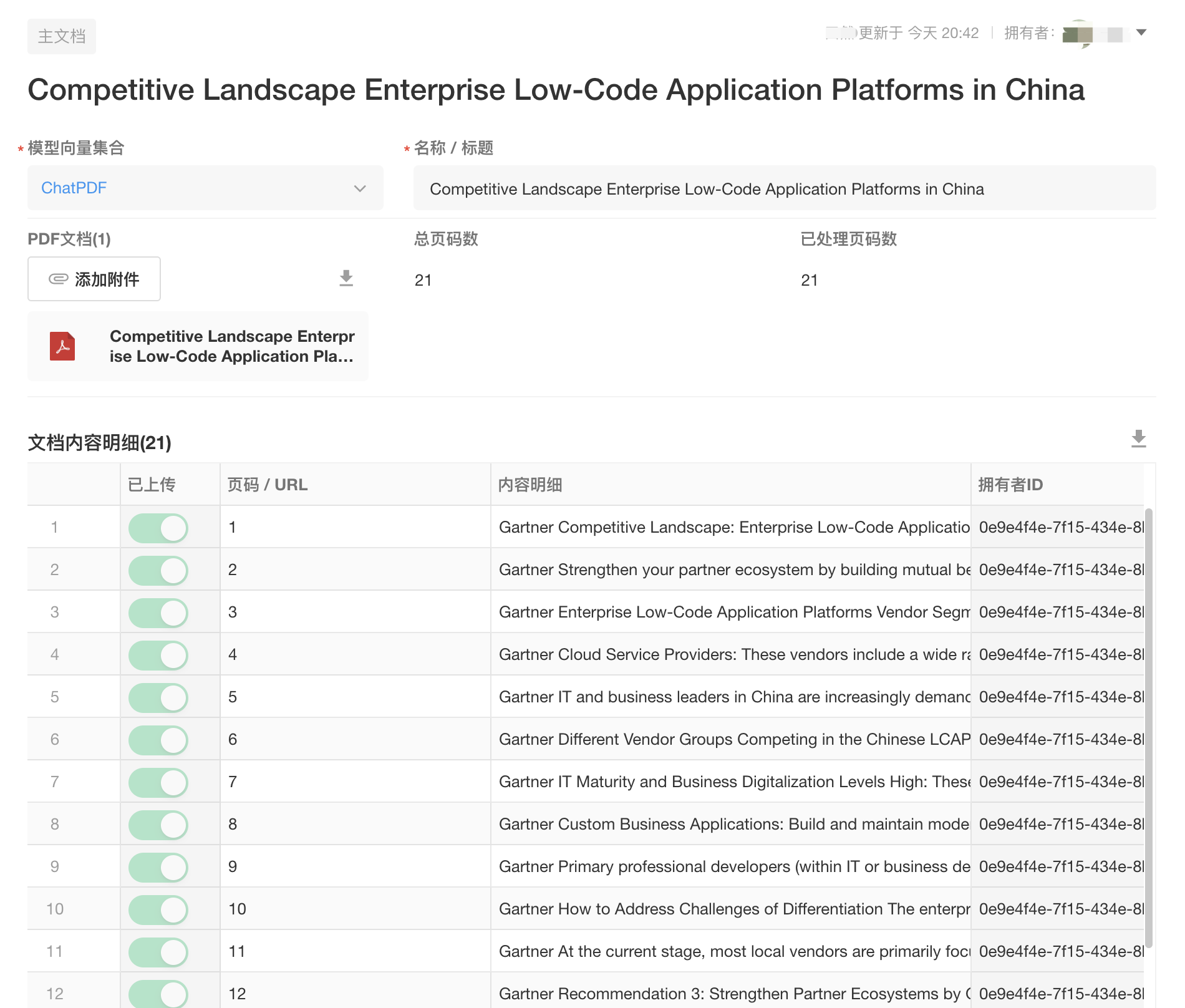 |
| PDF文档处理完成示例 |
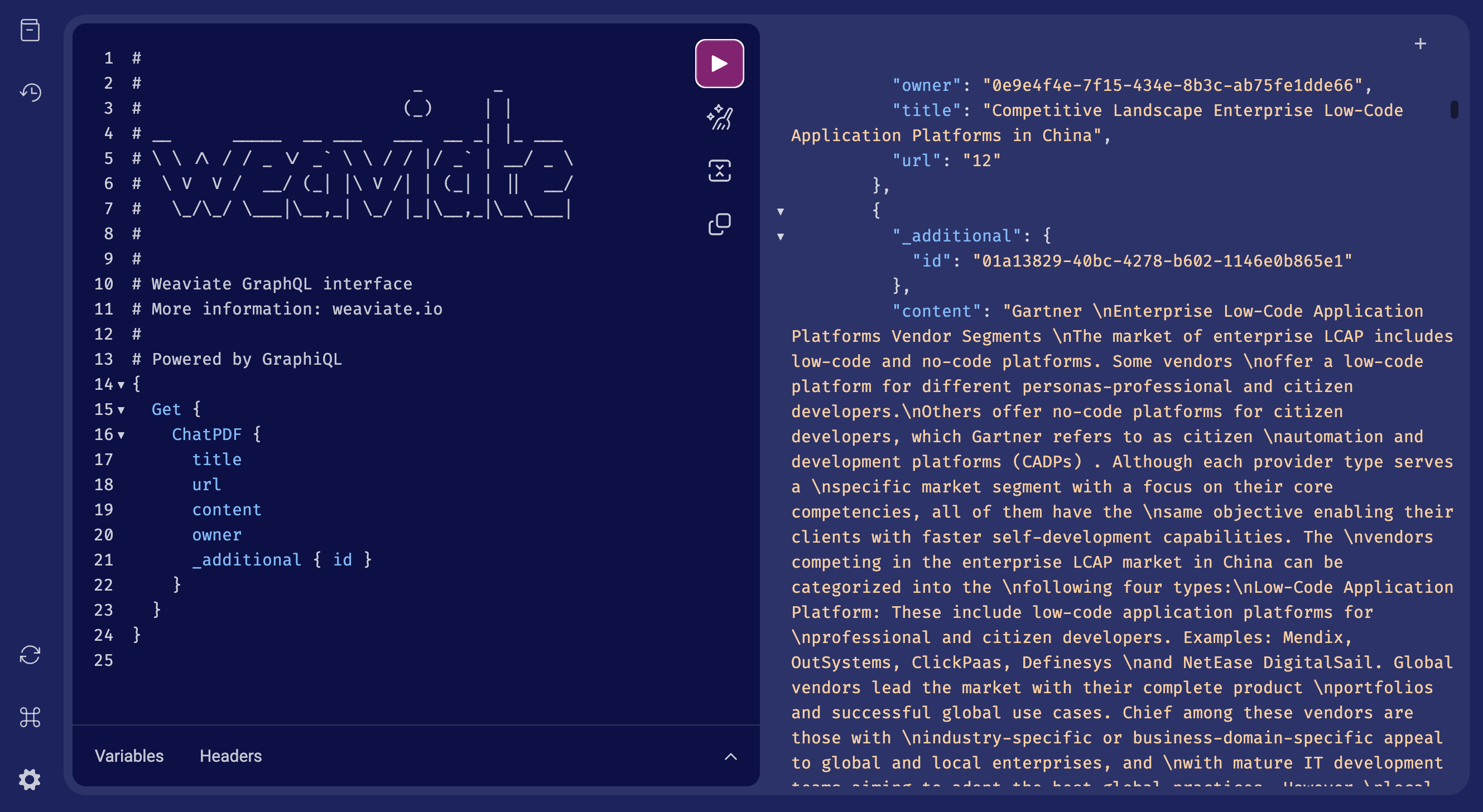 |
| Weaviate 控制台查询结果 |
三、向ChatGPT提问
在开发基于 ChatGPT 的问答应用时,最容易被用户接受的还是对话式的聊天UI。所以用明道云实现ChatPDF,可以直接基于它的内置 IM 工具来做。我用明道云做个人知识库时,就是基于这个IM做了一个「AI小助手」,也集成了今天讲的这个模仿ChatPDF模型进来,效果还是很不错的:
 |
| 把 chatGPT AI 助手集成到明道云 IM |
不过今天只是实现一个在1小时可以零代码完成的小Demo,我们就不用集成到IM里了,不然这篇文章可能1万字收不住了,我们直接用工作表来实现简单的提问效果。如果想和我一样集成到IM聊天工具中,可以自行研究一下明道云开放平台中关于处理聊天消息的一些API接口 [7]。当然,同样的思路集成在钉钉或者企业微信的机器人上也是可以的。
3.1 组合prompt
组合ChatPDF可用的prompt,是我们这个流程的核心部分。我们先设计一个工作表用来存放用户的问题和AI的回复,并用工作流实现自动生成对应prompt。
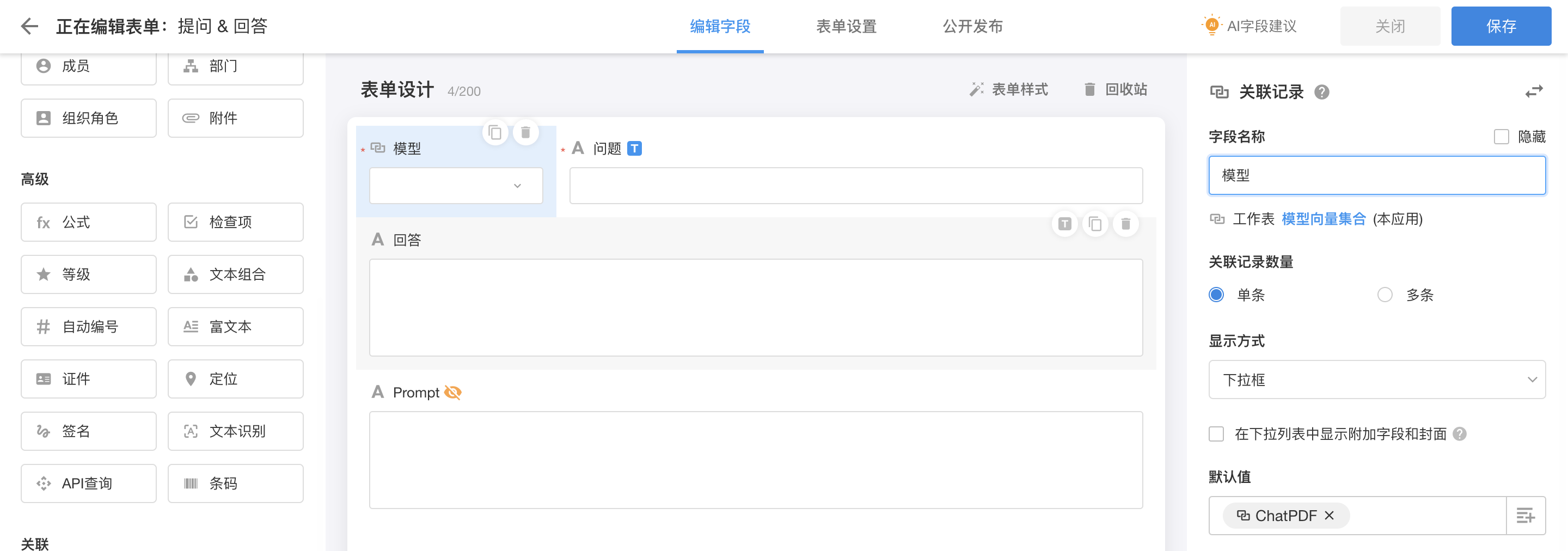 |
| 工作表:提问 & 回答 |
在创建工作流之前,还要去集成中心安装一下「ChatGPT」的API,因为我们要用到其中的文本嵌入接口把问题转成向量,进而用它去向量数据库中搜索语义最相似的页面内容,最后还要用它的chat接口进行提问。我们选择封装好的「一问一答」和「生成文本嵌入向量」API进行安装。
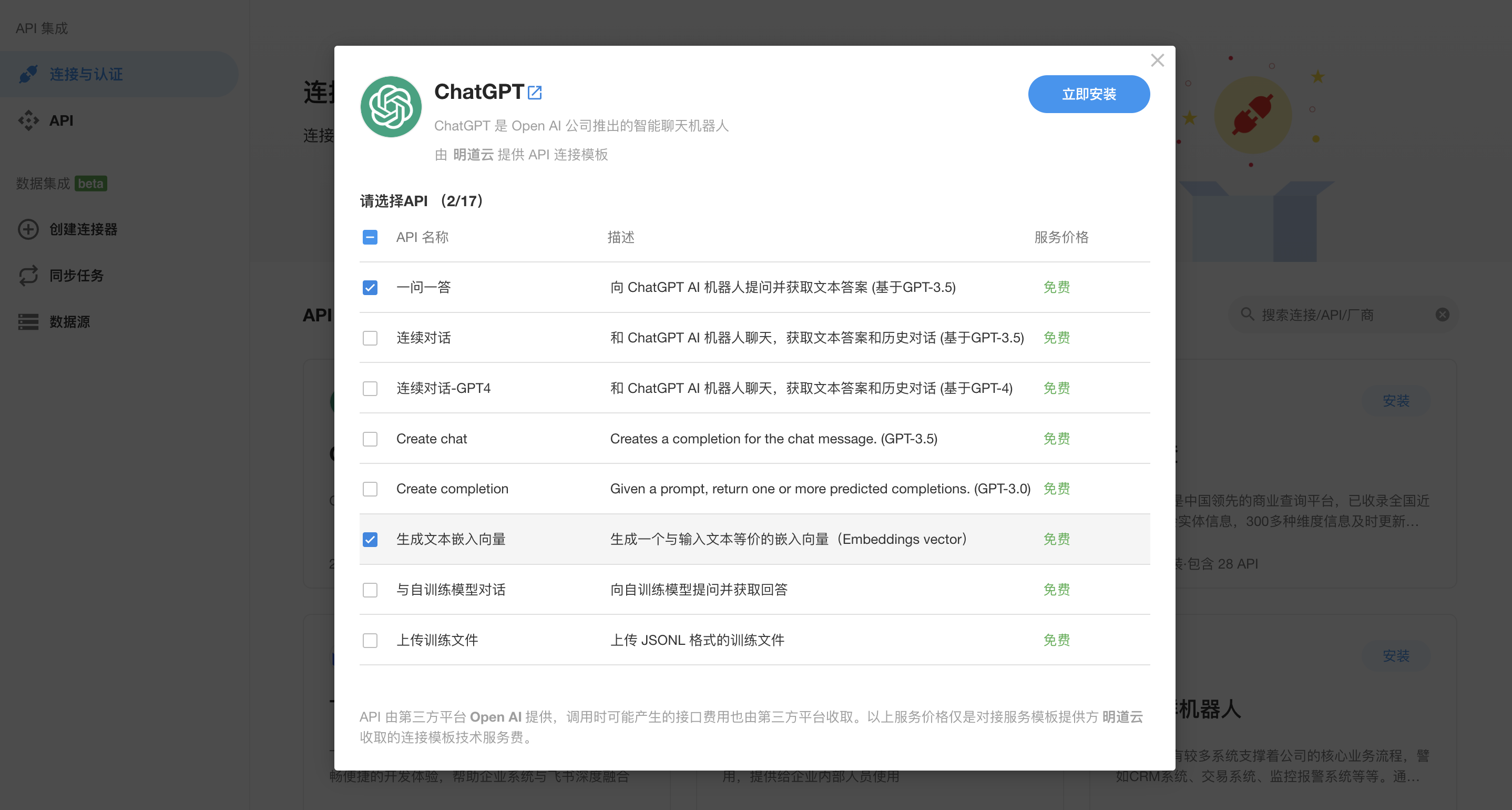 |
| 到集成中心安装 ChatGPT API |
这一部分的工作流其实也很简单,触发器设置为当工作表在新增或者更新时,如果「问题」字段有值则自动执行。流程中需要调用不同的集成API,再根据返回结果执行不同的分支。我这里为了记录下每个步骤的结果,多加了一些把请求结果更新到工作表存储起来的步骤,应用搭建好了之后它们都是可以删除的。
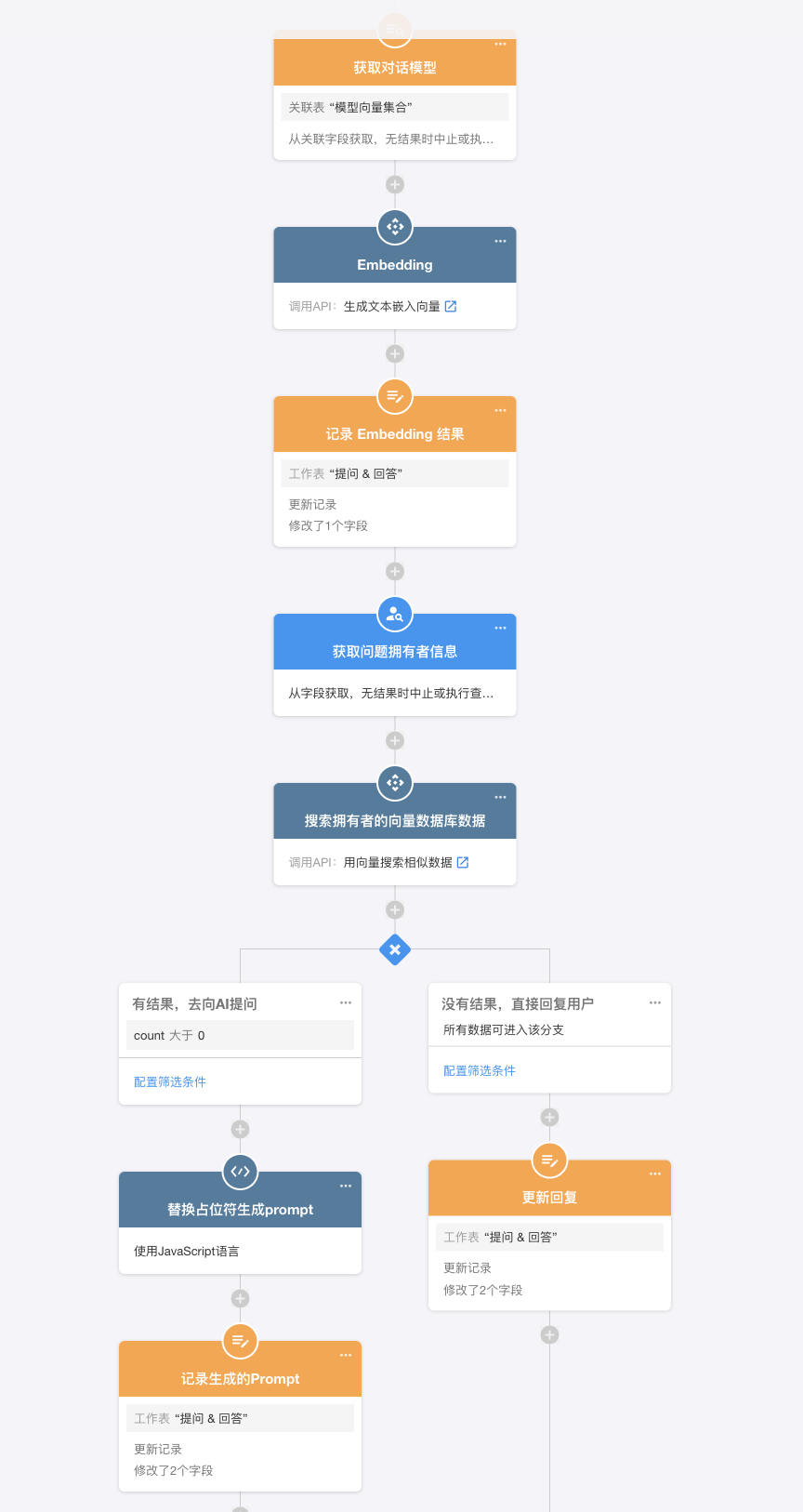 |
| 自动化工作流:生成 Prompt |
你可以往工作表添加问题进行测试了,正常情况下,如果有答案,它会生成Prompt,没有答案时会生成未找到答案的回复信息。
3.2 请求 ChatGPT 并组合回复结果
1个小时所剩无多,马上就到了要验收我们成果的时候了。这个步骤只需要在上一个工作流的有搜索结果分支内加上一个向ChatGPT的请求,然后在拿到AI回复的返回值后把PDF信息拼接进去就OK啦。
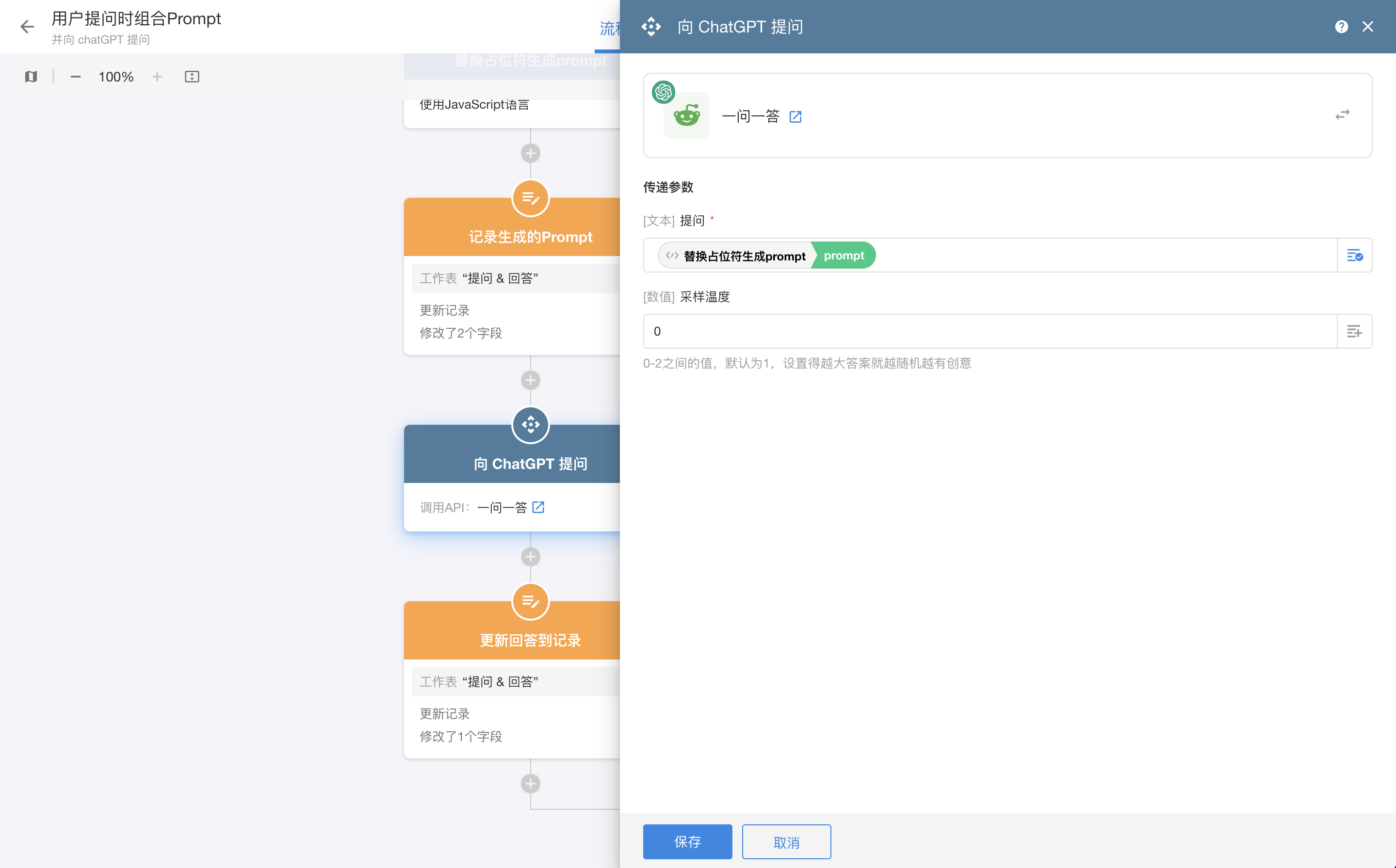 |
| 对于知识库的问答,通常采样温度 (temperature) 设置为0会得到更准确的回复 |
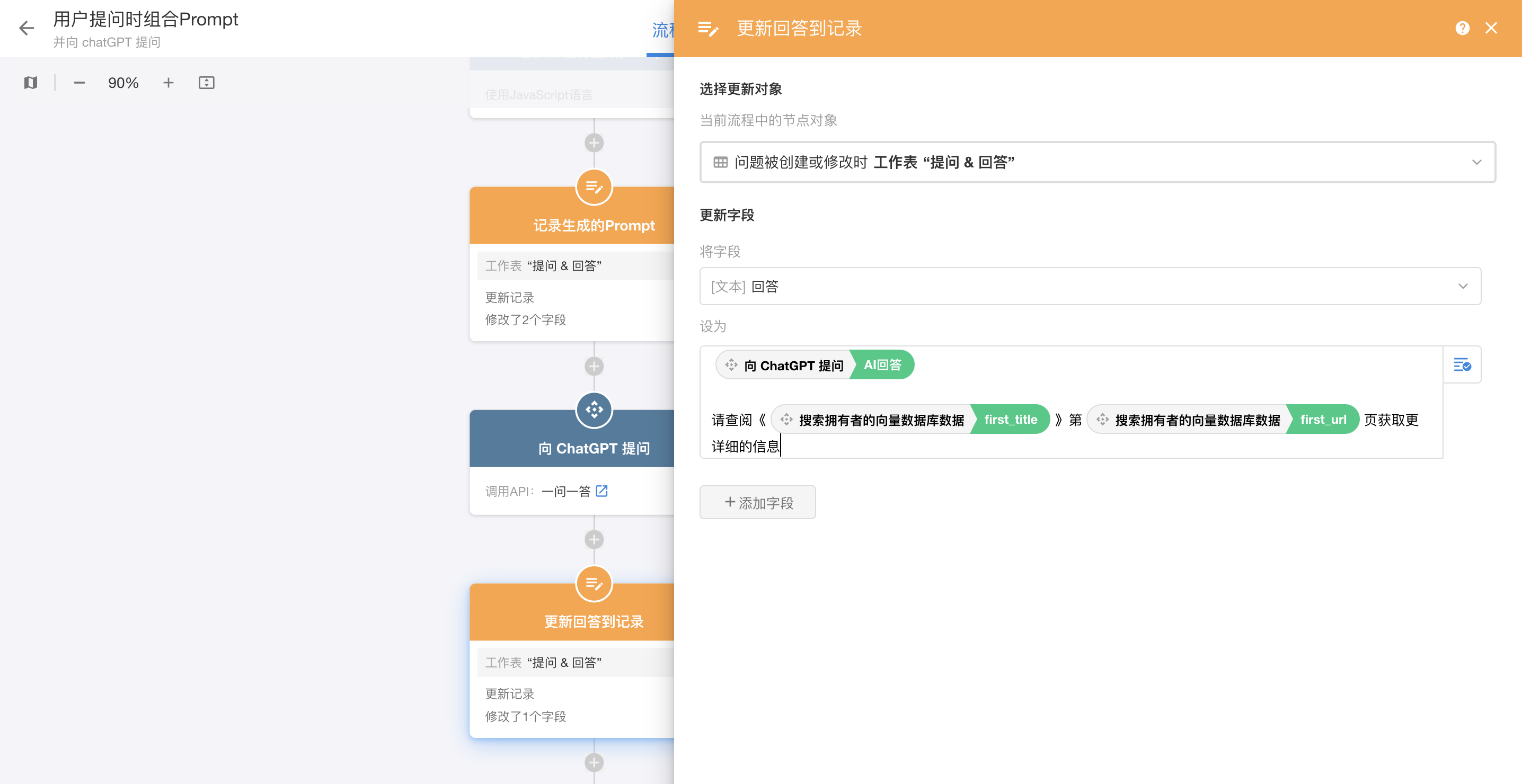 |
| 组合最终回复并更新到记录中 |
好了,当我们再次在工作表新建一条记录,提出问题后,稍等工作流运行完毕,就可以得到我们想要的答案了。你也可以将提问和回答的过程傅「封装业务流程」实现,再将这个流程开放为API,这样你在明道云平台之外,也可以使用这个能力了。下面是在记录详情中展示的最终效果:
 |
| 用工作表展示 ChatPDF 提问效果 |
写在最后
我们虽然用明道云快速地搭建了一个ChatPDF,但我相信你也看出来了,我们从头至尾设计的都是一个通用框架,而 PDF文档的分析只是它的其中一个应用场景。掌握了原理了之后,你可以在这个应用里放心的玩你感兴趣的其他基于自身业务内容的场景,测试和调整你的prompt模板,做出令人惊艳的成果。在这个例子里,你可以尝试一次性取2到3页的相关PDF,再提交给ChatGPT寻求答案,做出升级版的ChatPDF;你也可以尝试将采样温度(temperature)也作为模型的一个配置项……自己动手试试?
另外,上面这个Demo应用,已经上架到了明道云应用库,你可以直接在应用库搜索「ChatPDF」安装或下载使用 [8]。有关于这篇文章的的任何问题,也欢迎留言探讨。
引用
[1] 百度智能云「办公文档文字识别」:https://cloud.baidu.com/doc/OCR/s/ykg9c09ji
[2] ChatGPT Tokenizer (token计算器):https://platform.openai.com/tokenizer
[3] Sentiment Classification using Document Embeddings trained with Cosine Similarity :https://aclanthology.org/P19-2057.pdf
[4] ChatGPT API:https://platform.openai.com/docs/api-reference/chat/create
[5] Weaviate 控制台:https://console.weaviate.cloud
[6] 明道云封装业务流程介绍:https://help.mingdao.com/zh/flow_pbp.html
[7] 明道云开放平台文档:https://open.mingdao.com/document
[8] 明道云应用库-ChatPDF主页:https://mingdao.com/library/detail/64577707fb46e7c5df5a8b49

